Forecasts are created twice each day. As of May, 2013 Andy has the computer runs *starting* at 14:30Z (that is 7 AM- DST) each morning and at 0230Z (that's the evening run at 7:30 PM) for the next day. However, sometimes the NWS data causes delays, so be patient when that happens. From the start of those scheduled times, add roughly 25 minutes for each successive computer model run, of which there are five (WSC, MONT, WSC+1, MONT+1, WSC+2). Thus, if the first model run (WSC) begins at 7:30 AM, then the last model run (WSC+2) would not be completed before approximately 9:30 AM (7:30 plus 5 x 25 minutes for each run) (7:30 plus 125 minutes = 9:35) Note: Your mileage may vary (times are approx), and these times do not consider delays from NWS!
Note: Products indicate PST, not PDT ( Daylight Saving Time). Therefore, during the summer months, when we are using Daylight Saving Time, you should recognize that 1300 PST it actually 1400 PDT.
Links to Further Information:
RASP UniViewer
-not linked at this time! displays BLIPMAPs for the current day at multiple
times
RASP Archive
Viewer -not linked at this time! displays BLIPMAPs for the current
and previous days (one time per day only)
Parameter descriptions
BASIC thermal
forecast parameters - a short and simple
list of the parameters most important for thermal soaring
July 2002 SOARING magazine BLIPMAP article - a descriptive "first
thing to read" for potential BLIPMAP users, giving an overview of BLIPMAP predictions
Additional information
but intended for users of my traditional RUC and ETA BLIPMAPs, not these
RASP BLIPMAPs, so allowances must be made
Overview
These forecasts are intended to help the
meteorology-minded pilot better evaluate soaring conditions. The
maps are particulalry useful to cross-country soaring pilots, since
they allow evaluation of conditions away from the home field.
Utilizing the forecasts can require some self-education (though that
can't be too hard since over 2000 US pilots actively use BLIPMAPs in
the US) as individualized assistance is not provided. At first
glance the website can seem intimidating since so many parameters are
forecast - but most are "supplemental" forecasts to be used as needed
and many users normally look only at the three or four they have found to be
most useful, such as the expected lift strength or the maximum (dry)
thermalling height or cloud potential/height forecasts, looking at
additional parameters only under special conditions.
How are RASP forecasts produced ?
RUC and ETA BLIPMAP forecasts are obtained by
post-processing forecast files output from NCEP prognostic models, so
horizontal and vertical resolutions are determined by those used in
those models. But here I am running a prognostic model myself,
so am able to specify the vertical/horizontal grid (though of course
subject to limits of practicality). A WRF (Weather Research and
Forecasting) model is being initialized and marched forward in time at
30 second time intervals to produce forecasts at 3 hr
increments. Initial and boundary conditions come from the
larger-scale models run by NCEP. To increase accuracy, forecasts are produced for both a
larger-domain coarse grid (12 km) and a smaller-domain fine grid (4
km) nested inside it, but only results for the latter are
displayed. To produce a 1300 PST 1km forecast, after the preceding forecasts are complete, the model
is re-initialized from the 1000 PST 4km forecasts and a 4km/1.3km nested-grid
forecast run for 3 hours. BTW, the
data needed to make such runs is available globally, so in theory
such forecasts can be made for anywhere in the world !
Rationale and Accuracy
A higher resolution model is expected to better
predict those phenomenon which are "locally forced" and influenced by
terrain. But forecasts of higher accuracy than the RUC/ETA
BLIPMAPs are not guaranteed since: (1) all else is not equal, as the
RUC/ETA model uses different algorithms which might be more correct
than those used by the WRF, (2) the RUC/ETA models use a more refined
initialization procedure, and (3) any limited-area model is subject to
"boundary condition" errors, which for a large-area model such as
RUC/ETA are very far away and of little importance but here are much
closer and may have a significant influence. The question of
which model forecast is more accurate may depend upon what parameter
is being evaluated and can only be assessed through comparison to
actual conditions.
Of course one advantage of running a model is
that one has full control over it and can change its behavior.
The WRF has many, many parameters which can be adjusted. And one
of it's claims to fame is that is is modular, allowing use of
different routines, written by different people/groups, to make the
calculations which determine, say, cloud formation - so alternate
modules can be utilized to improve model accuracy. But on the
other hand one could spend a lifetime evaluating and changing things
to improve accuracy - this is what meteorologists at weather
prediction centers do, but I don't plan to do that myself!
BTW, the WRF model is considered to be the "model
of the future" for many operational weather predictions centers and is
a candidate to replace the ETA model at NCEP within the next few
years.
Notes and Caveats:
() One is not supposed to believe all the details of these
forecasts, particularly since the small-scale structure is constantly
changing yet one a few snapshots at different times are shown.
Rather, one should be looking for patterns.
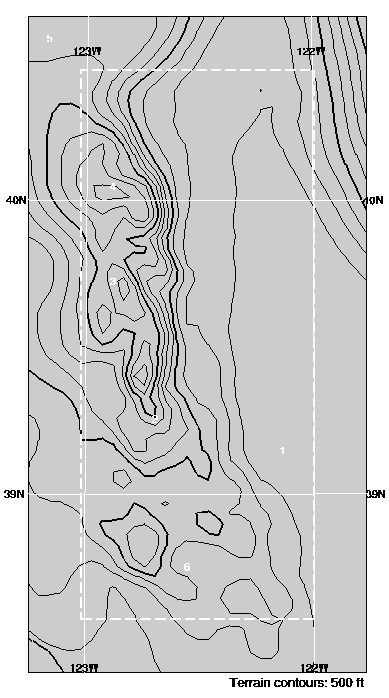
() Forecasts for points close to the boundary will be less
accurate than for those located nearer the center of the domain, due
to inevitable mis-matchings between the coarse and fine grids.
In particular, predictions of max/min BL vertical velocity are very
noisy and inaccurate near the boundary (particularly where boundary
condition problems exist). To remind users of this, a dotted
line marks the "frame" outside of which coarse-fine boundary
interaction problems are most prevalent.
() The "Explicit CloudWater Cloudbase" estimates are based on
cloud water predicted from model equations and problematical since there
is no simple criterion for differentiating "mist" concentrations from "cloud" concentrations.
The criterion presently used is a first guess.
() The "Cu Potential" and "Sfc. LCL" predictions are based on a simple formula which considers
only water vapor at the surface
() This model does not ingest as much observational data as do the institutional models
such as RUC and ETA, hence some effects are not included: for example, soil moisture
is neglected
() While many pilots are accustomed to using the 20km-RUC BL top
to estimate a maximum soaring height in terrain, that likely works
because 20km-RUC terrain heights are usually significantly lower than
actual ones. With better defined terrain on the 4 and 1 km
resolution grid, Hcrit is likely to become the more relevant
parameter. I suggest also looking at the BL depth and BL max/min
Upward Motion parameters as indicators for where maximum lift is
likely to occur.
() The present simulation is only a first cut, since to get
things running quickly many decisions have been on the basis of whatever
was easiest. Many choices must be re-examined in light
of experience gained with the present parameters. In particular,
I expect at some later time to alter the horizontal domain to reduce
some obvious boundary problems and to alter the vertical grid such
that a larger proportion of points occurs nearer the surface.
() The fact that these forecasts are only a snapshot in time of
a fairly noisy field should be particularly emphasized for the 1 km
resolution forecasts, as forecasts for, say, 30 minutes before or
after 1300 PST would look different. At this point it's difficult to
figure whether they will really add anything, but one never knows til
one tries.
() The "Vert. Velocity at 850mb" (and 700mb and 500mb) and
"Vert. Velocity Slice at Vert.Vel.Max" parameters attempt to forecast
mt. wave events, although strong vertical velocities resulting from
deep BL convergence can also be found in the plots. The first
parameter gives a plan view of vertical velocity at the 850mb level, a
height of roughly 5000 ft MSL and thus often above the BL top.
The second parameter is a vertical slice taken at a point of maximum
vertical velocity (as found at a height of around 5000 ft AGL within a
horizontal box which excludes the outmost edge of the domain) and
oriented parallel to the wind at that point, as indicated by a dotted
line on the plot of the first parameter (with left-right on the slice
always being left-right on the plan view). A label above the
plots gives the location and magnitude of the found maximum
value. Mt. wave predictions are best made using resultions no
larger than 4km, since a coarser grid generally does not resolve the
waves accurately. A key indicator of a mt. wave is its upwind
tilt with height, which is usually evident in the vertical
slice. For examples of mt. wave forecasts (at 1km resolution),
see these predictions of vertical velocity at 18,000 ft (500mb)
and in a vertical
slice.
() Because the intrinsic short-term time variability of the
atmosphere at scales as small as 1 km makes evaluations based on a
single-time forecast uncertain, I have added loops of parameter
forcasts for times near 1300 PST to aid assessment of short-term forecast
variations with time. A limitation of the present implementaion
is that colors can represent slightly different values at different
times, but the relative maxima are readily apparent.
Timeliness Issues
The forecasts are not as timely as I would like.
In particular, it woulld be best for launching pilots to have viewed forecasts
initialized from the early morning sounding data of that day since otherwise
the models depend upon soundings taken the previous evening and are thus less
accurate. But at present the 1300 PST forecasts from that data are not
available until after 8 AM PST (which will be 9 in the summer), later than I
would like.
The reason, of course, is that it takes time for sounding
data to be obtained and sent to NCEP, time for NCEP to process it and run their
model and produce output files, and time for me to download those files and
run my model and plot the output produced. NCEP model output becomes available
a bit over 2 hours after sounding release time and downloading takes around
10 mins - I have no control over things up to that point. My model run
time depends on many factors, notably the speed of the computer CPU and the
size of the domain modelled. At present the run time is around 2 hours
to produce forecasts at 1300 PST plus another 5 minutes for plotting.
This is slower than it might be because I have chosen to produce forecasts for
two different locations instead of just a single one, which increases the run
time by about 50%, and because the computer I am using (2.4Ghz dual Xeon) is
not the fastest available. On a faster computer running only a single
location the 1300 PST forecasts could be made available around 40-60 minutes
earlier. But since the RASP forecasts have not yet been shown to be useful,
for now I consider forecast timeliness a secondary issue.
And a yet-to-be-resolved conundrum is that several changes
I would like to make to improve forecast accuracy would also significantly increase
the run time and hence make the forecasts less timely. In particular,
in the interest of providing more timely forecasts I have used a larger time
step than is desirable, which decreases forecast accuracy. The crux of
the matter is that at present these forecasts are at the edge of what is possible
and practical - the good news is that as computer power increases in the next
years the timeliness and accuracy of the forecasts will improve.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}